

























Classification of AI news by AI Principle and policy area
A list of keywords was created for each AI Principle and policy area by selecting the most relevant related concepts in Event Registry’s search engine. To be classified under a certain AI Principle or policy area, a news article must a) be related to AI, and b) contain at least one of the concepts specified for that AI Principle or policy area in its title and/or abstract.
Selection of related online news by AI Principle and policy area
The most relevant news events from the past six months are shown in the “Related online news from Event Registry” lists in both AI Principle and policy areas dashboards. A news “event” is defined as a collection of news articles covering the same news. It serves as a measure of news impact.
News sentiment analysis
A ‘sentiment’ score is assigned to each news article and event to determine whether an article or event is ‘positive’, ‘neutral’, or ‘negative’. The sentiment score is calculated using the “VADER” (Valence Aware Dictionary and sEntiment Reasoner) open-source service, “a lexicon and rule-based sentiment analysis tool that is specifically attuned to sentiments expressed in social media.”
VADER contains a lexicon of words for which a sentiment score has been computed. The sentiment score is a floating value between -1 (negative) and 1 (positive). Additionally, VADER contains a set of rules to determine how sentiment is emphasised with individual words (for instance, “very” emphasises the sentiment, while negations inverse it). The sentiment score of an article results from the analysis of the first five sentences of the article. In practice, news articles rarely have extreme values close to 1 and -1; thus, scores below -0.1 are classified as negative; between -0.1 and 0.1 as neutral; and above 0.1 as positive.
This section describes the methodology used for the AI incidents and hazards featured on the AI incidents and hazards monitor (AIM) prior to November 2024.
Introduction
This section describes how Event Registry detects and categorises events considered to be AI incidents.
An incident or hazard refers to any event that might or might not lead to harm or damage. When such event results in harm or damage it is called an accident. An Artificial Intelligence (AI) incident or hazard refers to an unexpected or unintended event involving AI systems that results in harm, potential harm, or deviations from expected performance, potentially compromising the safety, fairness, or trustworthiness of the AI system in question.
For the purpose of monitoring AI incidents, Event Registry defines AI as the capability of machines to perform functions typically thought of, or at least thought of in the past, as requiring human intelligence. A system is a structured combination of parts, tools, or techniques that work together to achieve a specific goal or function. An AI system is any system that involves AI, even if it is composed of many other parts. Under these definitions, many systems that are not necessarily thought of as AI in a purely scientific manner, are included. For example, very simple credit scoring system using purely statistical methods can be considered as an AI system as they accomplish the task of determining the credit worthiness of an individual, which has traditionally been accomplished by other humans. Any time that part of a decision-making process is transferred to an algorithm, the system is considered to be an AI system. Other decision tasks where AI systems are involved include product recommendation systems, content moderation, and fraud detection. Similarly to decision tasks, perception tasks were also historically undertaken by humans. These can include tasks such as reading road signs in the context of a driver assistance feature in a car, recognising faces of known people from a surveillance camera, or recognising handwritten addresses in letter or packages for a postal service. Accidents and even incidents involving systems of all kinds are often reported (or forecasted) in the context of news media. Event Registry monitors world news and can detect specific event types reported in news articles, with over 150.000 articles English articles processed every day.
AI incident detection
In the context of a knowledge base, such as Wikidata [1], events or occurrences can be modelled structurally as statements composed of subjects (items), predicates (properties) and objects (values). To model an event in this structure, consider the following example:
| Subject | Predicate | Object | Wikipedia link |
| MH370 | Instance of | Flight disappearance | Malaysia Airlines Flight 370 |
Or, as a triplet: (MH370, instance of, flight disappearance) = (Q15908324, P31, Q104776655)
But news articles do not include data structured in this way. For the previously mentioned incident of the disappearance of flight MH370, one article stated:
Missing Malaysia Airlines plane: Flight MH370 carrying almost 240 passengers 'disappears' en route from Kuala Lumpur to Beijing.The core information of the event is present: It’s a flight, identified by the code MH370, that disappeared. The subject of this story is the “Disappearance of flight MH370”. Although the core information is present in the text, the “subject” hasn’t been explicitly defined in the way knowledge bases expect.
An alternative way of representing this event can be formulated in terms of the entities involved: (Malaysia Airlines, Incident, Flight MH370)
With the plain English meaning that Flight MH370 belonging to Malaysia Airlines was involved in an Incident. To bring back the discussion to AI incidents, consider the following sentence:
A Tesla Model S with Autopilot on failed to stop at a T intersection and crashed into a Chevrolet Tahoe parked on a shoulder, killing Naibel Leon, 22.This can be modelled as any of the following:
- (Tesla, AI Incident, Autopilot): An AI incident involving the company Tesla and its product, the Model S.
- (Tesla, AI Incident, Model S): An AI incident involving the company Tesla and its AI System, Autopilot.
- (Autopilot, AI Incident, Naibel Leon): An AI incident involving the AI System Autopilot which harmed Naibel Leon.
This formulation enables Event Registry to frame the problem of detecting an AI Incident as a supervised machine learning task, specifically, a text classification problem: given a sentence, does it express an AI incident involving a given pair of entities?
In order to classify pairs of entities in a sentence, the entities present in the text need to first be identified. To identify entities in the text, both Named Entity Recognition (NER) using spacy [2] and a separate Entity Detection and Linking system, Wikifier [3] are used. A supervised dataset is then created, which will be used by a learning algorithm to train a machine learning model to perform AI Incident event detection.
Model
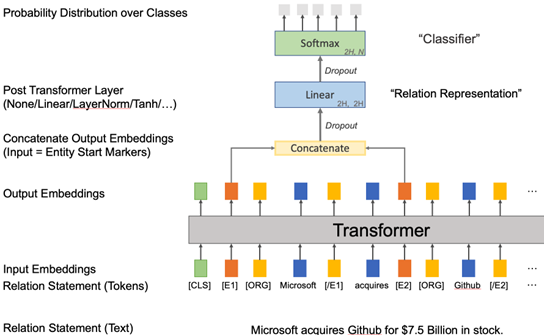
The model used to classify pairs of entities in the context of a sentence is based on a Transformer [4] Neural Network. It uses a BERT-like [5] pretrained language model, RoBERTa [6] to encode the text of a sentence. Before encoding, the sentence text is modified to surround the pair of entities being classified with special tokens and the entity type (e.g. organisation, location, product, …) is added before the beginning of the entity mention. This follows the procedure described in [7] for relation classification. The model architecture itself follows [8]: the transformer encodes the input text, the transformer output embeddings corresponding to the special tokens before each entity are then concatenated together into a single vector which is then passed to a classification head consisting of a linear layer followed by the Softmax activation function to produce a normalised probability distribution over the possible event classes. Notably, what is the probability that the pair of entities in that sentence corresponds to an AI Incident.
Dataset
The problem of detecting an AI Incident is formulated as a supervised machine learning task. The learning process is commonly known training the model. That implies there must be learning examples which are used to learn the parameters of the model. These examples correspond to the model inputs and the associated model targets. As a set of examples, they are commonly called a training set. In order to estimate the performance of the model on unseen data it is necessary to also have a set of examples that are not seen by the model during training. In this case, we call that set of examples the validation set. Examples for training this model includes both positive and negative examples. Positive examples are examples of AI Incidents, while negative examples are not AI incidents. The negative examples were chosen to be semantically similar to positive examples and thus can be considered as “hard examples”.
| Data split | Positive examples | (Hard) Negative examples |
| Training | 766 | 996 |
| Validation | 245 | 94 |
Performance metrics
Performance metrics for classification follow definitions closely linked to statistical hypotheses testing. They are defined in terms of the truth value of the model’s prediction and the value of the target example. A correctly classified examples is called a True Positive (TP) if the corresponding target value is positive, and True Negatives (TN) if the associated target is negative. An incorrectly classified example is called a False Positive (FP) if the example’s target is negative, and a False Negative (FN) if the target is positive. Given a supervised set of examples, it is common to define its performance in terms of relative rates called precision and recall:
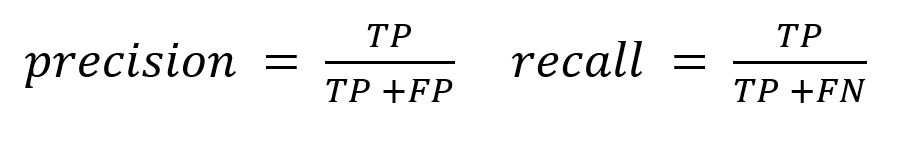
Since these two metrics ultimately represent two different types of errors, they are complimentary. When either necessary or desirable to use a single metric that encompasses both types of errors, it is common to use an F-score, typically the F1-score defined as the harmonic mean of precision and recall:
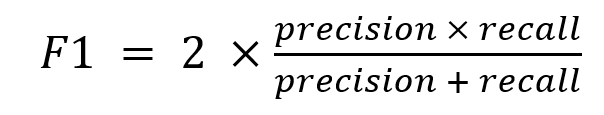
In cases when there are multiple classes beyond just positive and negative, called a multiclass problem, it is common to average class specific F1 scores. There are two common types of averages commonly used: the micro-average which is biased by the class frequency and the macro-average which considers all classes as equally important regardless of their respective frequencies. Averages reported in this document are micro-averages. Metrics are written as percentages and round to the nearest whole number. Experimental results:
| Task | Precision | Recall | F1 |
| AI incident | 89 | 90 | 90 |
Categorisation of AI incidents
AI Incidents are categorised according to several characteristics of the event. These characteristics include those related to the harm caused. Namely, the level of severity of the incident, the type of harm caused, and the general group to which the harmed parties. Additional characteristics are included including industry and AI principle. The following taxonomy is used for each of these characteristics:
Severity:
- the incident resulted in death;
- serious but non-fatal physical injury occurred;
- a non-physical harm, psychological, financial, reputational, very minor injury, other;
- a hazard, denoting a potential, hypothetical, future harm, threat or unrealised danger;
Harm Type:
- physical harm to a person or persons, injury or death;
- psychological harm to a person or group including manipulation, deception, or coercion;
- financial to a person or organisation;
- reputational harm to a person or organisation;
- harm to the public interest;
- violation of human or fundamental rights;
- no harm, not specified, or unknown.
Affected stakeholders:
- consumers, people who own or use the product or service;
- workers, employees or job applicants;
- a business or businesses or stockholders in the business;
- researchers or scientists;
- a government, government agencies or officials;
- minorities;
- public, people not otherwise included in this list (e.g. citizens, pedestrians, passers-by, etc.);
- unknown, not specified.
Industry:
- agriculture;
- arts, entertainment and recreation;
- business processes and support services;
- construction and air conditioning;
- consumer products;
- consumer services;
- digital security;
- education and training;
- energy, raw materials and utilities;
- environmental services;
- financial an insurance services;
- food and beverages;
- government, security and defence;
- healthcare, drugs and biotechnology;
- IT infrastructure and hosting;
- logistics, wholesale and retail;
- media, social platforms, marketing;
- mobility and autonomous vehicles;
- real estate;
- robots, sensors, IT hardware;
- travel, leisure and hospitality.
AI principle:
- accountability;
- fairness;
- human wellbeing;
- privacy and data governance;
- respect of human rights;
- robustness and digital security;
- safety;
- sustainability;
- transparency and explainability;
- democracy and human autonomy.
Level and Type are defined as multiclass classification problems, meaning only one of the values can be true for each of them. Multiple groups can be harmed in the same incident and thus it was defined as a multilabel classification problem. Note that the label “unknown” in this case is only used if none of the other groups were identified as being harmed.
Model
The model for categorising AI incidents is a multitask model with a shared encoder. The encoder is distilroberta-base [9] and each task has a dedicated classification head which uses the output of the transformer corresponding to the special input token “[CLS]“ as in [5]. The input consists of the sentence where the AI Incident was detected, plus the next two sentences.
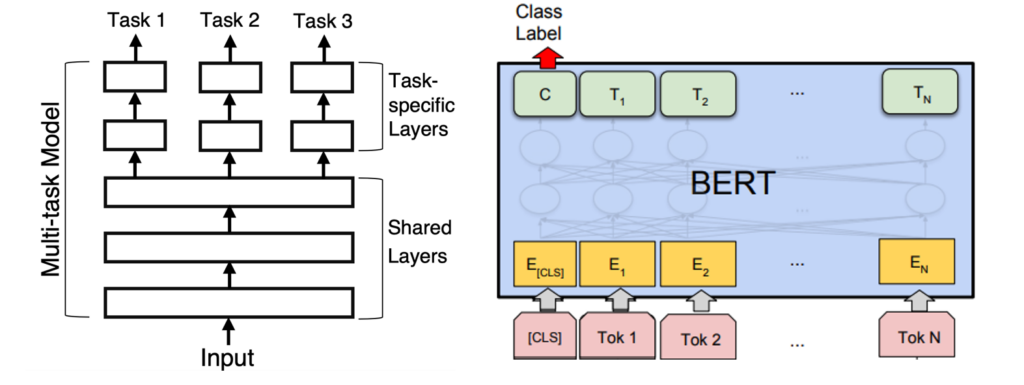
Dataset
The dataset for categorisation of AI Incidents corresponds to the positive examples in the dataset for detecting AI Incidents. Experimental results:
| Task | Precision | Recall | F1 |
| Harm level | 76 | 76 | 76 |
| Harm type | 57 | 57 | 57 |
| Harmed groups | 69 | 66 | 67 |
References
[1] Vrandečić, Denny, and Markus Krötzsch. “Wikidata: a free collaborative knowledgebase.” Communications of the ACM 57.10 (2014): 78-85. https://www.wikidata.org
[2] https://spacy.io
[3] Brank, Janez, Gregor Leban, and Marko Grobelnik. “Annotating documents with relevant wikipedia concepts.” Proceedings of SiKDD 472 (2017). https://wikifier.org
[4] Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems 30 (2017).
[5] Kenton, Jacob Devlin Ming-Wei Chang, and Lee Kristina Toutanova. “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.” Proceedings of NAACL-HLT. 2019.
[6] Liu, Yinhan, et al. “Roberta: A robustly optimized bert pretraining approach.” arXiv preprint arXiv:1907.11692 (2019).
[7] Zhou, Wenxuan, and Muhao Chen. “An Improved Baseline for Sentence-level Relation Extraction.” Proceedings of the 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing. 2022.
[8] Soares, Livio Baldini, et al. “Matching the Blanks: Distributional Similarity for Relation Learning.” Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019.
[9] Sanh, Victor, et al. “DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter.” arXiv preprint arXiv:1910.01108 (2019). https://huggingface.co/distilroberta-base