

























A joint report by the International Development Bank (IDB) and the OECD

Through the fAIr LAC initiative and the OECD.AI Policy Observatory, the IDB and the OECD have partnered to move the AI policy discussion from high-level principles to practice and implementation. This toolkit is a concrete step in this direction.
The Data Science Toolkit for the Responsible use of AI uses the AI system lifecycle as the guiding framework to provide technical guidance for public policy teams that wish to use AI technologies to improve their decision-making processes and outcomes. For each phase of the AI system lifecycle – planning and design, data collection and processing, model building and validation, and deployment and monitoring – the toolkit identifies common challenges when using AI in public policy contexts and outlines practical mechanisms to detect and mitigate them.
Policy makers and their technical teams should be accountable for the proper functioning of an AI system at each phase of its lifecycle. A chapter of the toolkit explores accountability-related issues in the use of AI for public policy and outlines practical mechanisms to address them.
>> GET THE DATA SCIENCE TOOLKIT
Why this toolkit?
This toolkit identifies areas of risk and recommends mitigation measures to avoid unintended negative outcomes. Undesirables include wasted resources due to inadequate targeting and other outcomes that undercut what decision-makers are seeking to achieve.
Although there are a significant number of principles in support of ethical AI, they provide high-level guidance on how it should or should not be developed, and there is very little clarity on the best practices for putting those principles into operation (Vayena 2019). This toolkit is not intended to regulate or explain what the aims and objectives of decision-making bodies and actors should be.
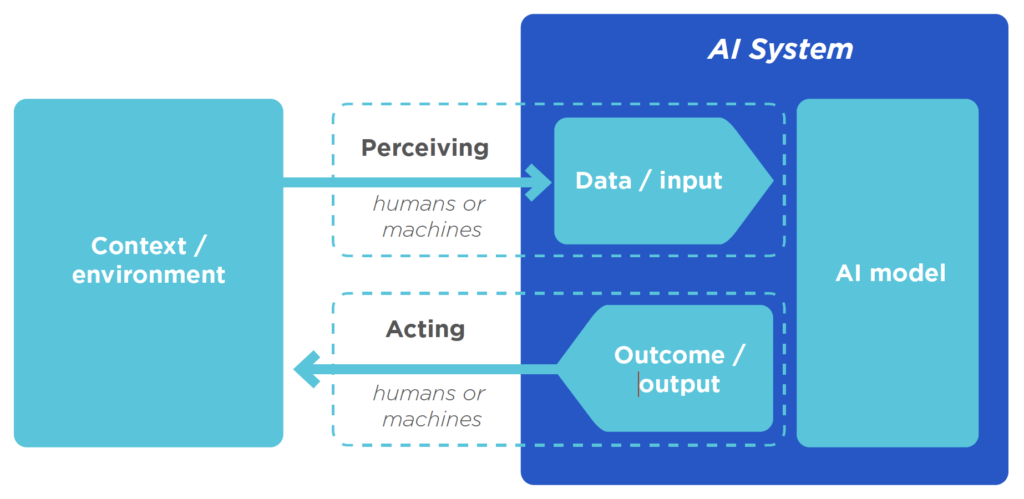

Who is the data science toolkit for?
This toolkit is for technical teams working on machine learning algorithm applications for public policy. However, it covers challenges common to other applications of this technology. It does assume that readers have basic knowledge of statistics and programming, but it does include brief descriptions and additional references for new concepts.
The toolkit includes workbooks with example challenges and solutions. Different types of models (linear, tree-based, and others) and implementations (R, Keras, Xgboost) illustrate how these problems arise regardless of the choice of a particular tool or algorithm. Although the codes and examples were developed in R, all the topics and methodologies applied and described in this toolkit can be implemented in any other programming language.
All the material in this toolkit is reproducible according to instructions in the repository (https://github.com/EL-BID/Manual-IA-Responsable), which contains a Dockerfile describing the infrastructure dependencies for its replication. The R programming language is used along with the following packages: tidyverse, recipes, themis, rsample, parsnip, yardstick, workflows, tune, knitr, and patchwork.