


























These tools and metrics are designed to help AI actors develop and use trustworthy AI systems and applications that respect human rights and are fair, transparent, explainable, robust, secure and safe.
GovLLM
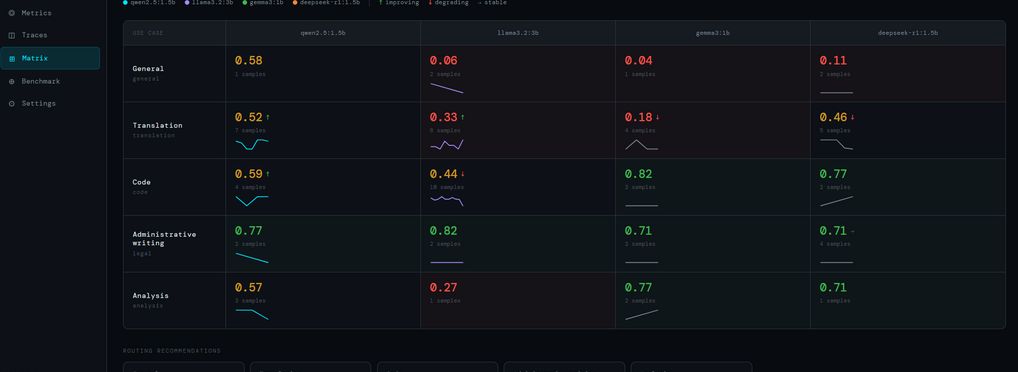
GovLLM is an open-source runtime governance framework for LLM systems. It treats regulatory compliance as a continuous signal derived from production observability rather than a static audit verdict. A panel of small language model judges evaluates each response against governance profiles anchored to EU AI Act, GDPR, and ANSSI (French National Cybersecurity Agency) criteria. Inter-judge disagreement is reframed as a regulatory uncertainty signal warranting human arbitration. Runs fully on-premise with no data leaving the operator's infrastructure.
GovLLM addresses a structural gap in AI governance: most compliance frameworks assess AI systems once, at deployment, and assume conformity holds over time. This is the compliance fiction: a system evaluated at t₀ may produce non-compliant outputs at t₀ + n, with no mechanism in place to detect it.
The framework implements governance from metrics: regulatory compliance derived continuously from production observability. Its core components are:
- A panel of specialised small language model judges (1.7B-7B parameters), each assigned to a specific regulatory criterion (transparency, data privacy, non-manipulation, prompt injection resistance, human oversight), running fully on-premise via Ollama.
- A governance-driven routing architecture in which model selection is determined by accumulated compliance scores rather than latency or cost alone.
- A four-zone model lifecycle (test → human validation → production → quarantine) implementing AI Act art. 9 continuous risk management requirements.
- A compliance gate mechanism that automatically excludes underperforming models from routing based on per-criterion minimum thresholds.
The framework has been empirically validated through a ground truth corpus of 49 annotated prompt/response pairs across five regulatory criteria, evaluated by four small language models under three question-order conditions (585 judge runs, 2340 individual assessments). Results are published in a peer-reviewed preprint: "Who judges the judges? Governance from metrics: a runtime framework for continuous LLM compliance monitoring" (arXiv:2605.24737, May 2026).
Key empirical findings: agreement rates range from 51.5% to 69.1% with no single model dominating across all criteria; question order alone degrades agreement by up to 25 percentage points; a specialised panel (Profile-as-jury) outperforms the best single judge by 10.9 percentage points. Three structural failure modes in small regulatory judges are documented and formalised.
The annotated ground truth corpus is publicly available on Hugging Face. The full implementation is open-source under EUPL 1.2.
About the tool
You can click on the links to see the associated tools
Developing organisation(s):
Tool type(s):
Objective(s):
Impacted stakeholders:
Target sector(s):
Country/Territory of origin:
Lifecycle stage(s):
Type of approach:
Maturity:
Usage rights:
License:
Target groups:
Target users:
Stakeholder group:
Validity:
Enforcement:
Geographical scope:
People involved:
Required skills:
Technology platforms:
Tags:
- ai compliance
- eu ai act
- ai runtime monitoring
- llm governance
- llm-as-judge
- open-source
- regulatory evaluation
- small language models
- inter-judge disagreement
Use Cases
Would you like to submit a use case for this tool?
If you have used this tool, we would love to know more about your experience.
Add use case


 Partnership on AI
Partnership on AI