

























Overview
The AI Incidents and Hazards Monitor (AIM) was initiated and is being developed by the OECD.AI expert group on AI incidents with the support of the Patrick J. McGovern Foundation. The goal of the AIM is to track actual AI incidents and hazards, as defined by the OECD, in real time and provide the evidence-base to inform related AI policy discussions.
The AIM detects AI incidents and hazards from reputable international news outlets. The data is provided by Event Registry (ER), a news intelligence platform that monitors and aggregates world news by processing over 150 000 news articles daily. Event Registry detects events, which are clusters of news articles reporting on the same happening. These events are tagged with related concepts. The events provided by Event Registry to AIM are limited to those that include AI concepts.
While recognising the likelihood that these incidents and hazards only represent a subset of all AI incidents and hazards worldwide, these publicly reported incidents and hazards nonetheless provide a useful starting point for building the evidence base.
An open submission process following the common reporting framework for AI incidents is currently being developed to complement AI incidents and hazards from news articles. Other next steps include complementing incidents and hazards with court rulings and decisions by supervisory authorities wherever they exist.
The data collection and analysis for the AIM is done to ensure, to the best extent possible, the reliability, objectivity and quality of the information for AI incidents and hazards.
Definitions
Thanks to the work of the OECD.AI expert group on AI incidents an AI incident and related terminology were defined. Published in May 2024, the paper Defining AI incidents and related terms, defines an event where the development or use of an AI system results in actual harm as an “AI incident”, while an event where the development or use of an AI system is potentially harmful is termed an “AI hazard”.
- An AI incident is an event, circumstance or series of events where the development, use or malfunction of one or more AI systems directly or indirectly leads to any of the following harms:
(a) injury or harm to the health of a person or groups of people;
(b) disruption of the management and operation of critical infrastructure;
(c) violations of human rights or a breach of obligations under the applicable law intended to protect fundamental, labour and intellectual property rights;
(d) harm to property, communities or the environment.
- An AI hazard is an event, circumstance or series of events where the development, use or malfunction of one or more AI systems could plausibly lead to an AI incident, i.e., any of the following harms:
(a) injury or harm to the health of a person or groups of people;
(b) disruption of the management and operation of critical infrastructure;
(c) violations to human rights or a breach of obligations under the applicable law intended to protect fundamental, labour and intellectual property rights;
(d) harm to property, communities or the environment.
These definitions were built based on the definition of an AI system as described in the OECD recommendation on AI of 2019 and revised in 2024.
- An AI system is a machine-based system that, for explicit or implicit objectives, infers, from the input it receives, how to generate outputs such as predictions, content, recommendations, or decisions that can influence physical or virtual environments. Different AI systems vary in their levels of autonomy and adaptiveness after deployment.
Information Transparency Disclosures
- Background: Your use of the OECD AI incidents and hazards monitor (previously AI Incidents Monitor) (“AIM”) is subject to the terms and conditions found at www.oecd.org/termsandconditions. The following disclosures do not modify or supersede those terms. Instead, these disclosures aim to provide greater transparency surrounding information included in the AIM.
- Third-Party Information: The AIM serves as an accessible starting point for comprehending the landscape of AI-related challenges. As a result, please be aware that the AIM is populated with news articles from various third-party outlets and news aggregators with which the OECD has no affiliation.
- Views Expressed: Please know that any views or opinions expressed on the AIM are solely those of the third-party outlets that created them and do not represent the views or opinions of the OECD. Further, the inclusion of any news article or incident does not constitute an endorsement or recommendation by the OECD.
- Errors and Omissions: The OECD cannot guarantee and does not independently verify the accuracy, completeness, or validity of third-party information provided in the AIM. You should be aware that information included in the AIM may contain various errors and omissions.
- Intellectual Property: Any of the copyrights, trademarks, service marks, collective marks, design rights, or other intellectual property or proprietary rights that are mentioned, cited, or otherwise included in the AIM are the property of their respective owners. Their use or inclusion in the AIM does not imply that you may use them for any other purpose. The OECD is not endorsed by, does not endorse, and is not affiliated with any of the holders of such rights, and as such, the OECD cannot and do not grant any rights to use or otherwise exploit these protected materials included herein.
Methodology for monitoring AI incidents and hazards
Since November 2024, incidents and hazards are identified and added to the AIM through the following steps.
Historical incidents and hazards, collected prior to November 2024, are currently being retrospectively annotated using the same methodology to ensure consistency.
- Events tagged with AI-related concepts – including artificial intelligence, machine learning, generative AI, self-driving car and facial recognition – are retrieved from Event Registry.
- LLMs are used to classify AI-related events into three categories: AI incidents, AI hazards or unrelated events, as defined above. This classification is based on the event summary provided from Event Registry. The classification follows a two-step process: first, a smaller model (OpenAI’s GPT-4o mini) filters out events that seem unrelated to AI incidents and hazards; next, a larger model (OpenAI’s GPT-4o) reclassifies the remaining events to confirm whether they are incidents or hazards.
- Individual news articles are classified into incidents and hazards using LLMs, following the same process as for events. In this case, however, article content is used instead of event summaries to enhance reliability. This ensures that all articles related to an event are relevant and that the event’s classification (as incident or hazard) is supported by its articles. If some articles are classified differently, the event will adopt the most common classification among them. For example, if an event is originally classified as an incident but has three news articles, and two of those are classified as hazards, the event’s label will be changed to “hazard”. If none of the articles for an event are classified as an incident or hazard, then the event as a whole is reclassified as “unrelated”.
The steps (2) and (3) help ensure that only pertinent events are included on the AIM. - Each event is enriched with relevant metadata, including an event title, summary, the harm type, severity, affected stakeholders, and the country where it occurred, among others. This metadata is LLM-generated (OpenAI’s o3-mini) from the top three articles of each event, selected from different news outlets. Articles are ranked based on their outlets’ ranking in their respective country. This approach ensures a balance between the popularity of the outlets and fair geographical representation. Currently, the summary and metadata are generated at the time the incident or hazard is added to the AIM.
- Similar events are grouped by analysing their summaries and identifying related events in AIM using cosine similarity. For each new incident or hazard, the top 10 closest summaries (i.e., “embeddings”) from existing events in AIM are identified. An LLM (OpenAI’s o3-mini) is then used to assess whether any of these similar events can be clustered together. If no similar events are found, a new incident or hazard is created.
Update frequency
The pipeline runs daily, processing events from one to four days ago. This time frame optimises the amount of information captured by AIM, allowing media outlets to cover and report on relevant events, while Event Registry processes and clusters them.
In particular, news articles related to ongoing incidents or hazards are retrieved from Event Registry for four days after an event and are added to the relevant event in AIM. This approach ensures that AIM captures the most relevant articles during the peak of media coverage. Articles appearing after this timeframe are likely to be misclassified as a separate event.
Summary table and process map of the methodology
The following table and process map summarise the steps taken to identify events as AI incidents or hazards; enrich the reports with metadata; and cluster events into AI incidents and hazards.
| Identification and classification | Data enrichment | Clustering |
| – AI events and their articles are classified as AI incidents, hazards or unrelated based on OECD definitions. – On average, about 1 000 AI events are analysed daily, resulting in around 10 AI incidents or hazards. | AI incidents and hazards are enhanced with metadata and criteria from the reporting framework, such as title, summary, country, industry, and affected stakeholders | – Articles are added to events up to 4 days after the event was first registered. – Before being uploaded to AIM, new incidents and hazards are checked against existing events and grouped as relevant. |
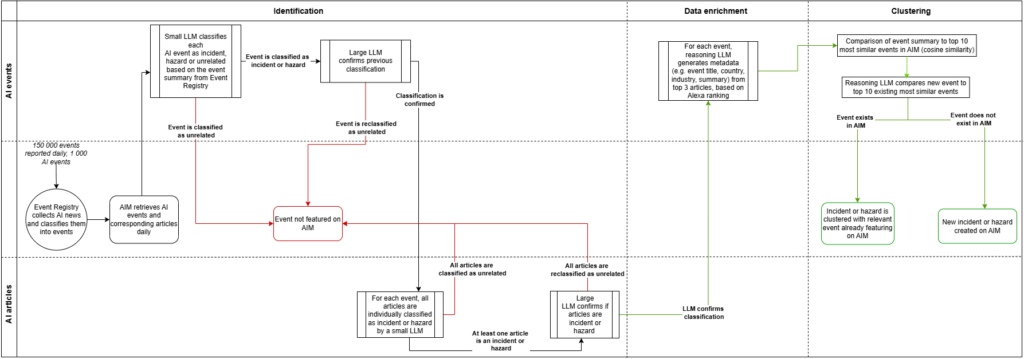
To note, an AI event contains multiple news articles. The articles are added to events up to 4 days after an event was first registered. the AIM detects on average 30 incidents and hazards per day.
Prior to November 2024, AI incidents and hazards were classified and included on the AIM using traditional machine learning techniques. Please find this archive for more information.