


























How to handle GDPR data access requests in AI-driven personal data processing





More and more services and products use AI to create content and support decisions, increasing personal data processing. But what happens if individuals, i.e. data subjects, try to access their personal data being processed by AI systems? The EU General Data Protection Regulation, GDPR, says they can, but AI complicates things.
The tensions between AI and data protection have practical and regulatory implications. Processing personal data with AI is not prohibited under any European legislation per se, and using AI does not exclude the data protection rules. Even the Commission’s proposal for the Artificial Intelligence Act, the most comprehensive legal text regulating AI to this date, stipulates that it shall apply without prejudice to the GDPR. However, due to the data-intensive nature of modern AI systems, applying data protection principles and tools is challenging. The most practical tool for doing so is probably the Data Subject Access Request, DSAR. UK ICO and Irish DPA reports show DSARs have the highest share of complaints received in 2022 in the UK (36.79%) and Ireland (42%).
Handling DSARs can be complicated, but here are some ideas for mitigating these challenges.
What are DSARs under the GDPR? The right of access and the information to be provided
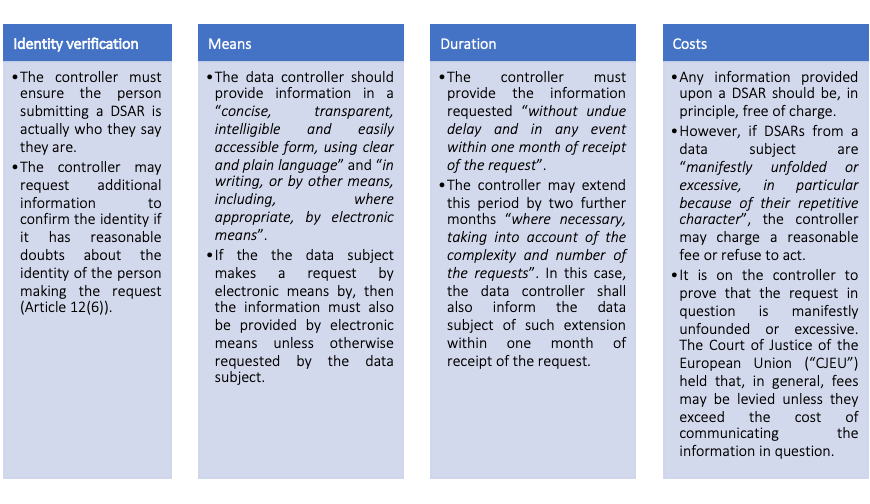
Under Article 15 of the GDPR, DSARs are requests from the data subject to exercise the right of access to the following information from the data controller when and if their personal data are processed:

The right of access and how AI complicates DSARs
The general principles to exercise this right are spelt out under Article 12:
There are several risks involved in processing personal data with AI systems. Regarding the DSARs, there are four significant challenges stemming from the technical nature of AI systems:
- The difficulty in determining the scope of the information: The so-called black-box nature of some modern AI systems and the fact that all information gets subsumed by an AI model in formats that are illegible to most people complicates matters. This may make it difficult for the data controller to grasp to what extent each data point affects the output. In AI systems used for hiring or termination, data points, such as name and education, are used to train and create output. However, it is almost impossible to know precisely which point is the most influential one or whether bias has developed.
The Court of Justice of the European Union, CJEU, recognised this problem in a recent judgment, where the Court stated that “given the opacity which characterises the way in which artificial intelligence technology works, it might be impossible to understand the reason why a given program arrived at a positive match”.
This also makes it challenging to determine what information to provide. The data controller should provide readily available information, but is it required to go beyond that and share information inferred by the model or even the model itself? The answer depends on the model, but, in principle, no, it isn’t. Allowing data subjects to request all AI-generated information and the model itself would open the door to abusive efforts to obtain commercially sensitive information from AI developers. Recital 63 of GDPR rightfully stipulates that “[this] right should not adversely affect the rights or freedoms of others, including trade secrets or intellectual property and in particular the copyright protecting the software.”
- The difficulty in explaining how AI models work to data subjects: Understanding the technical nature of modern AI can be challenging, even for experts, depending on the model. However, even with more explainable models and explainability measures implemented, such as model cards, it may still be challenging to convey the explainability metrics and risks to data subjects concisely and transparently, with clear, plain language.
AI systems are automated. Accordingly, data controllers must provide “meaningful information about the logic involved, as well as the significance and the envisaged consequence of such processing for the data subject”.
There are two problems here. First, providing meaningful information may be difficult or impossible due to how the model works. Secondly, the amount of information and its meaning could be unclear. For example, with AI systems used to review CVs, should the employer disclose the use of AI? Should it disclose the techniques and algorithms used to train the model? Should it also explicitly inform the data subjects that their applications may not be shortlisted after an AI-driven CV review?
- First, the data controller should disclose the use of AI but be careful with the level of technical detail. If the target audience is not comprised of experts, providing too many technical details may exhaust the data subject rather than provide useful information.
- Second, the data controller should undoubtedly disclose the most likely adverse effects of the processing. But it should not be required to single out every effect, no matter how remote.
- The difficulty in establishing the excessiveness of requests: DSARs are often drafted in broad language, requesting all information about data subjects. The challenges of handling such broad requests are not limited to AI, and the data controller should provide as much information as possible. However, Recital 63 states, “Where the controller processes a large quantity of information concerning the data subject, the controller should be able to request that, before the information is delivered, the data subject specify the information or processing activities to which the request relates”.
The question is whether an AI system’s data controller could refuse to provide information on the grounds that such a request is “manifestly unfolded and excessive” purely due to the use of AI. Again, the answer depends. For example, requesting the whole model could be considered excessive. However, the data controller cannot refuse to provide information solely because it processes personal data via an AI system for two main reasons.
- Arguing as such would completely undermine the applicability of Articles 15(1)(h) and 22 and clearly be against the spirit of the GDPR.
- Under Article 25 of the GDPR, “Data protection by design and by default”, data controllers must design their systems and implement necessary measures during development and deployment. Trying to avoid responding to a DSAR since the technology makes such a request excessive may violate that article.
- Requests concerning data erasure and rectification can lead to model deletion: The rights to rectification and the right to be forgotten or erased are two distinct rights in GDPR Articles 16 and 17, respectively. They are closely linked to the right of access in practice, as a request for these may precede or follow a DSAR.
Some wonder if these provisions allow data subjects to request the deletion of an AI model that may contain their personal data or generate outputs based on it. In principle, they do, but only if the model in question is designed to generate highly personalised outputs. The effect of individual data points in an AI model varies, but it gets lower as the training dataset becomes more extensive. In LLMs, the effect of a person’s name on the model is negligible. Hence, unless there are practical indicators that the model is generating or leaking personal data, these rights should not be used to delete or retrain the model.
Another area that needs clarity in handling a DSAR following a request for rectification or erasure is whether the data controller keeps the model after deleting the personal data. This depends on the answer to the last question. If the model is not generating or leaking personal data and there is no practical indication it might, the data controller can handle such a DSAR as usual without disclosing that it keeps the model. However, if the model generates or leaks personal data, it may require the data controller to disclose that in its response and trigger other obligations under the GDPR.
How the EU AI Act does not directly address DSARs
Different instruments, including legislation, can address the risks mentioned above. An important question is whether the EU AI Act, a framework tailor-made for AI systems, addresses any of them. In short, it does not explicitly regulate DSARs. Instead, the EU AI Act provides that it shall not affect the data protection rules. However, the data governance, technical documentation, and transparency requirements for high-risk AI systems under Articles 10, 11, and 13 facilitate handling DSARs related to these systems.
How can DSARs and AI-based risks be balanced?
Despite concerns, AI will have to process personal data in some domains, and it is clear that DSARs and AI systems are here to stay. Still, there needs to be a balance between the interests of individuals in the protection of privacy and the interest of society in developing AI systems. Here, we believe that three measures need to be taken into account while seeking to maintain that balance:
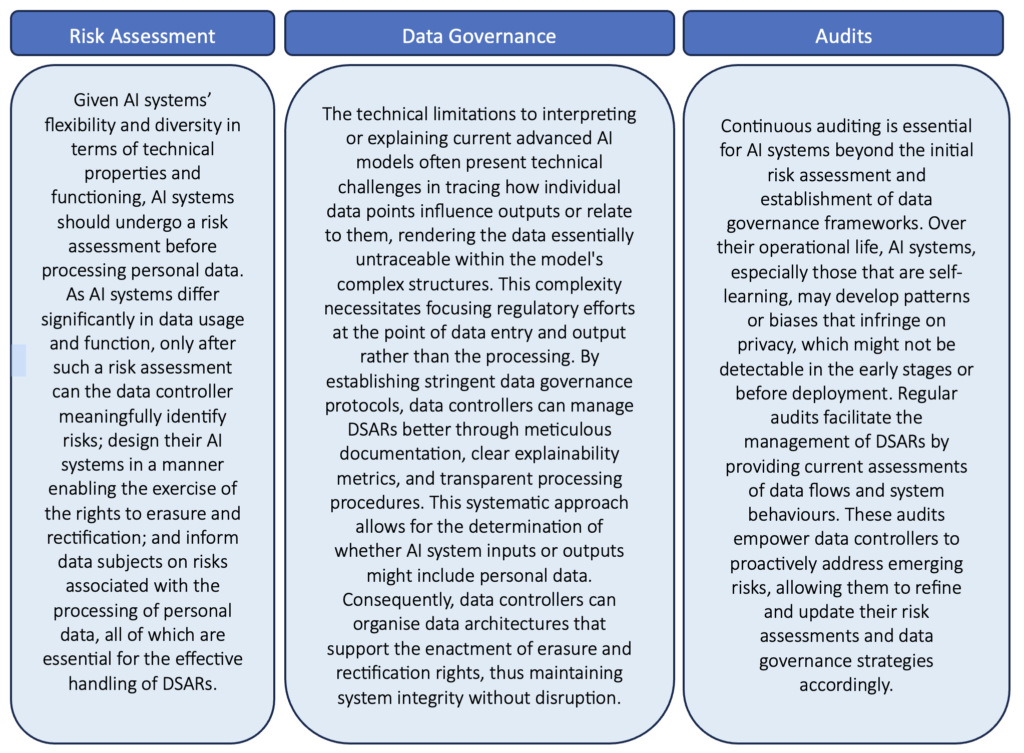
Implementing a comprehensive risk assessment system and robust data governance protocols is crucial for data controllers utilising AI systems to process personal data. These measures help pinpoint potential risks and discern whether the AI’s inputs or outputs are personal data. This awareness facilitates crafting AI systems and development processes that efficiently accommodate the management of DSARs by ensuring that modifications or deletions can be made without disrupting the AI’s operations or discarding existing models. This may include minimising the amount of personal data used, precluding specific sensitive data from processing, or intercepting and preventing potential data breaches. Similarly, any outputs identified as risky or derived from sensitive data can be proactively purged. Regular audits are essential to validate that the risk assessments and mitigation strategies remain current and effective.
The flexibility of these measures allows for tailored implementation, considering the unique circumstances of each case. Although such breadth in the guidelines introduces uncertainty that may pose challenges in execution and adherence, it is essential to recognise that such adaptability is designed to cater to AI technology’s evolving and varied nature. This should not be viewed as a weakness but as a strategic characteristic to effectively regulate a field marked by rapid advancement. The primary goals, per the principles of DSARs, are to thoroughly comprehend the data protection concerns associated with a specific AI system, communicate these risks to data subjects clearly, succinctly, and transparently, and make the potential subsequent requests effective.



