


























Risk thresholds for frontier AI: Insights from the AI Action Summit






How many hot days make a heatwave? When do rising water levels become a flood? How many people constitute a crowd?
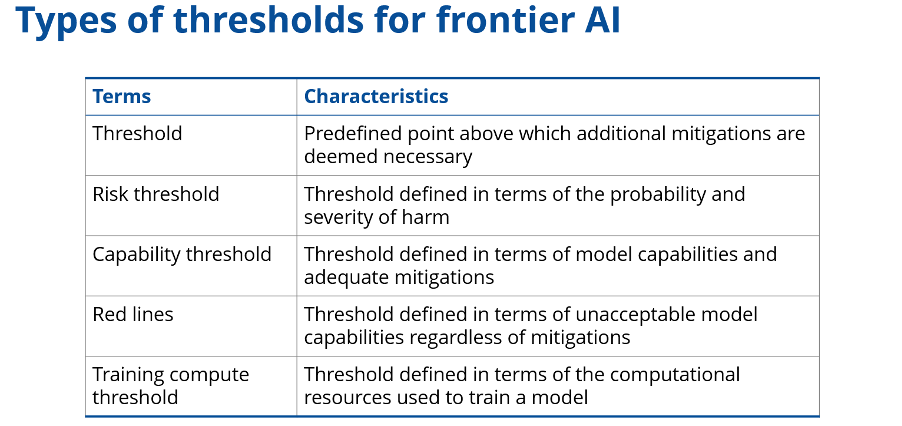
We live in a world defined by thresholds. Thresholds impose order on the messy continuum of reality and help us make decisions. They can be seen as pre-defined points above which additional mitigations are deemed necessary.
There is increasing interest in thresholds as a tool for governing advanced AI systems, or frontier AI. AI developers such as Google DeepMind, Meta, and Anthropic have published safety frameworks, including thresholds at which risks from their systems would be unacceptable. The OECD recently conducted an expert survey and public consultation on the topic of thresholds.
To deepen this conversation, the UK AI Security Institute (AISI) and the OECD AI Unit convened leading experts at the AI Action Summit to discuss the role of thresholds in AI governance. Representatives from the nuclear and aviation industries joined experts from the Frontier Model Forum, Google DeepMind, Meta, Humane Intelligence, SaferAI, and the EU AI Office. This blog captures some key insights from the discussions.
Beware the analogy
The nuclear and aviation industries use precise, probabilistic thresholds to articulate acceptable levels of risk. For example, the US Federal Aviation Administration (FAA) sets a threshold that the probability of ‘failure conditions that would prevent continued safe flight and landing’ should not exceed 1 x 10–9 (one in a billion) per flight-hour (Koessler et al., 2024).
Participants highlighted the challenges of setting similar thresholds for frontier AI risks. Challenges included the fact that (a) frontier AI systems are, by definition, novel and constantly evolving, with limited data on past incidents and (b) frontier AI systems are general-purpose. This makes it difficult to estimate the risks that they could pose. There was nonetheless pushback on the basis that the nuclear industry was still novel when thresholds started to be discussed.
Measurement matters
Participants noted that thresholds are useful when they can be assessed against. Many developers establish capability thresholds that they can evaluate through model evaluations; other organisations, including governments, can also assess capabilities. They discussed challenges related to measuring capability, risk, and compute thresholds.
Participants discussed the value of conducting multiple types of model evaluations, including human studies. Human studies are crucial for tracking known risks and identifying new ones. They may also help raise awareness of the capabilities of frontier AI systems and kickstart discussions with non-AI experts about how the technology should be developed.
Several participants raised the challenge of translating between thresholds set at different levels of abstraction, such as those related to risk and capability. This can impact the efficiency, robustness, and validity of thresholds. Uncertainty surrounding the process of ‘risk modelling’ has resulted in diverse approaches to threshold setting.
An emerging consensus
The safety frameworks published by AI developers focus on mitigating a similar group of risks. Participants pointed out that AI developers often set capability thresholds for CBRN (chemical, biological, radiological, nuclear), cybersecurity, and autonomy risks. Nonetheless, there were warnings about applying the same standard to every domain when evidence bases differ. For example, cybercrime is an established issue, while autonomy risks are more novel.
Participants also warned against groupthink. Various stakeholders could prioritise different risks depending on their expertise, area of influence, or perceived value. Thresholds for CBRN, cybersecurity, and autonomy risks should be regularly reassessed in light of a broad spectrum of potential harm scenarios.
Setting thresholds should be inclusive
Thresholds address the question: how safe is safe enough? Participants acknowledged that thresholds are, therefore, laden with value judgements. Quantification bias can conceal the extent to which this is true for probabilistic risk thresholds.
Participants emphasised the importance of continuous engagement among governments, AI developers, civil society, academia, and the public in establishing thresholds for AI risks. The discussions at the AI Action Summit started this urgent process.
Open questions: measurement and coordination
AISI and the OECD AI Unit welcome further research and collaborations on thresholds. Some open questions raised by discussions at the AI Action Summit include:
- Measurement: What accounting and evaluation methods should be adopted for each threshold type? How can we reduce gameability and incentivise responsible risk management?
- Coordination: How can we promote collaboration between AI and non-AI experts in threshold setting and build consensus?
- Response: What does effective threshold governance look like? What actions should be taken if thresholds are crossed?
If you are working on these questions, get in touch: thresholds@dsit.gov.uk



