


























New AI technologies can perpetuate old biases: some examples in the United States






Artificial Intelligence (AI) models that recommend and drive decisions may perpetuate historical social inequities through biased outcomes if left unchecked. As AI models become more prevalent across societal systems and industries, human-centred values such as fairness must be incorporated into the model development process. Additionally, simple explanations of outcomes should be provided, giving affected individuals a chance to understand and challenge decisions. With these kinds of guardrails, AI actors can detect, reduce, and mitigate biases, so using AI becomes more of an opportunity to lessen disparities than a risk of perpetuating unfair outcomes.
Different uses of AI bring different levels of risk. For example, a recommendation on a coffee drink or TV programme can lead to low-impact outcomes. How much harm would you incur if the coffee tasted terrible? What would you lose if you did not like the TV programme? However, there are areas where AI-generated recommendations can have greater consequences, such as financial access and law enforcement. These high-impact recommendations could drive decisions that are unfair and negatively affect marginalized communities, furthering historical inequities.
Biased outcomes impact human lives
Throughout history, human decision-makers have been systemically unfair and discriminatory to certain groups of people providing biased outcomes that influence and drive decisions, no different to what an AI model with bias may do. For example, models with facial algorithms have been repeatedly proven to be less accurate for people with darker skin, resulting in racial bias cases of misidentification. For example, a 25-year-old male from Detroit, USA, was arrested for felony theft after the city’s facial recognition software misidentified him. If the results had not been assessed further, an innocent man would have been mistakenly arrested and imprisoned for a portion of his life, perpetuating the inequity of wrongfully imprisoning people of colour.
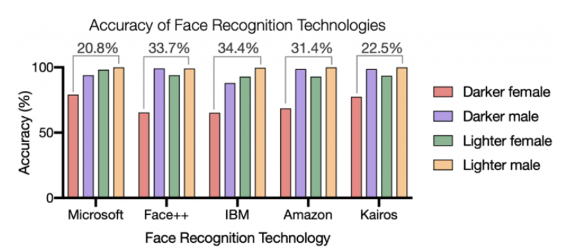
Source: Racial Discrimination in Face Recognition Technology | Harvard GSAS Science Policy Group
This raises a few questions:
- How can those responsible for building AI systems prevent such biased and unfair outcomes?
- How can those affected by biased outcomes receive explanations to challenge such decisions?
Models are built by humans, who may be biased or may inject historically biased data sets as model inputs, whether intentionally or unintentionally. So, humans have a key role in identifying, reducing, and mitigating bias before and after outcomes are released.

The decision-maker’s role: prioritize fairness in the model development process
Bias can be introduced at any stage of the model development process, and decision-makers such as business leaders, subject-matter experts, developers, and testers have a key role in asking critical questions to ensure a model is fair. Questions include what bias means in a given context. For instance, social bias can be defined as outcomes that are systematically less favourable to individuals within a group when there is no relevant difference to justify such harm. On the other hand, statistical bias can be defined as the difference between a model’s predictions and the value being predicted, i.e., accuracy. It is important to decide which definition to optimize and to identify fairness as a priority in all models.
Furthermore, it is vital to define the model’s goal beforehand to ensure alignment between the model’s outputs and the outcomes of the process. It is also important to question if there is alignment between the decision-makers’ values and the model’s objective. For instance, if the model concerns human subjects, decision-makers should consider whether the use case should be selected at all, depending on value alignment and potential impacts. Going back to a previous example, cameras have been shown to represent skin tones innacurately in certain situations, so should one rely on camera data to build facial recognition systems that make high-stakes decisions?
The Allegheny Family Screening Tool is an example concerning human subjects, where developers were not only mindful of the harm a biased algorithm could cause, but also proactive in their efforts to minimize it. The model aimed to assist a county in deciding whether a child should be removed from their family due to maltreatment. It relied on historical data that had unwanted discriminatory biases. Through checks and balances applied during the development process, such as prioritizing open and transparent design, it identified inequities in the tool. As a result, the county used the model only as an advisory tool and assistant in decision making, and trained users on its fallacies and gaps.
Preliminary research asserts that regulating algorithmic assistance and verifying algorithmic outputs by a human decision-maker or subject-matter expert, instead of the algorithm itself could provide a critical fallback to an algorithm and drive more equitable outcomes. During verification, it is important to assess the data sample used to train the AI model and ask questions, such as:
- Why was this particular sample chosen? Was it cherry-picked to prove a certain narrative?
- How was the data collected? Was it randomly sampled? Is it representative of the population to which it is being applied, or are certain groups left out of the dataset?
- What is the tolerance for error? Who stands to gain or lose from errors in model outcomes?
Since models work within dynamic environments and variables, they must be maintained, monitored, and improved to ensure that performance does not drift and equitable outcomes are ensured for as long as the model is in use.
Critical model development is a team sport, where anyone involved in the process can contribute to ensuring equitable outcomes. It is the collective responsibility of model decision-makers to refuse to apply certain algorithms or models if bias is apparent, and critically question the introduction of AI products into our lives and their potential impacts on society. Only if we all actively participate, and all views are represented, can we can identify the blind spots and account for underrepresented groups in model outcomes, to contribute to making our society fairer, more transparent, and more accountable.
A consumer’s right to interpretability: AI models need to be explained in human-centred terms
Interpretability is key to fighting unfair outcomes, especially if they have significant impacts on or pose risks to consumers. Interpretability is an explanation of how a model comes to the predicted outcome in a human-understandable format, which allows those adversely affected to understand and challenge decisions and verify fairness. An interpretable model needs to explain “why” a person of colour was identified as a criminal or rejected from a loan decision, making it easier for the person in question to judge whether the decision was biased.
In general, there are certain classes of AI models that inherently produce more interpretable outcomes, such as linear models. Researchers from Duke University’s Prediction and Analysis Lab note that these models should be prioritized for high-stakes decision problems over black box predictive models, which are models that are too complicated for a human to understand but are commonly considered to be more accurate. In the case when black box models are selected to increase model performance, there are methods that can help explain feature importance or interaction, with some limitations. Two popular explainability techniques used for complex models trained on highly dimensional data are Local Interpretable Model-Agnostic Explanations (LIME) and SHapley Additive exPlanations (SHAP).
LIME is a technique that approximates a black box model with a local, interpretable model to explain each individual prediction. LIME is a popular technique for interpretability; however, the approach has been critiqued for producing explanations that are not robust and have low fidelity or goodness of approximation.
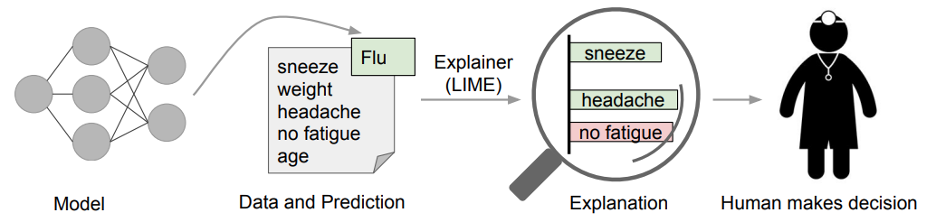
Source: “Why Should I Trust You?” Explaining the Predictions of Any Classifier
SHAP is an alternative technique derived from game theory principles that breaks a prediction down to show the impact of each feature. SHAP is a popular method for explainability; however, the approach is critiqued for its computational intensity.
Given the limitations of current explainability methods, there is still room for experts to define and develop methods that produce easy-to-understand explanations. For instance, recent research from MIT advocates for the use of taxonomies to make features more interpretable.
Humans need to comprehend and challenge how an algorithm came to a result, and this makes interpretability key in the process. Interpretability also provides insight into how a model can be improved, revealing where biases are present and providing an opportunity to mitigate biases through clear explanations.
If managed properly, AI can produce fair outcomes and help reduce historical societal inequities
Algorithms used in AI models have the potential to help reduce discrimination relative to human decision-making and to predict outcomes much more accurately than humans. Credit scores calculated by AI algorithms, for instance, have improved financial institutions’ abilities to score credit-poor consumers. In this case, AI could expand access to credit and other financial services to customers that would otherwise be left out of the financial system. The use of an AI model is an alternative way to tackle biased human decision-making, reducing face-to-face discrimination in select markets.
With the right safeguards in place, AI can bring forth benefits to society that limit or stop societal inequities, but we humans, from model designers to those affected by a model’s outcome, must play a key role in helping to identify, mitigate, and reduce bias throughout the model’s lifecycle, and in advocating for interpretability to challenge unfair outcomes before and after they are released.
Disclaimer: The views expressed in this post are those of the authors and do not necessarily reflect the position of the Federal Reserve Bank of New York or the Federal Reserve System. Any errors or omissions are the responsibility of the authors.
*The Data & Analytics Office (DAO) at the Federal Reserve Bank of New York drives the enterprise data and analytics strategy for the Bank and owns data policy and governance standards. The DAO is responsible for establishing a data foundation for the Bank, building capabilities while setting standards and measurements for data quality, compliance, security, and retention of our data assets. In addition, the DAO focuses on innovating through and driving advanced analytics in collaboration across the Federal Reserve System.

From the AI Wonk


What gets measured gets managed: How the OECD and European Commission quantify AI investment
October 8, 2025 — ![]() 3 min read
3 min read

There are many ways to minimise water use related to AI operations, but they may not be what you think
October 7, 2025 — ![]() 7 min read
7 min read