


























BigCode: toward open AI governance processes in LLMs for coding





BigCode is an open scientific collaboration working on the responsible development and use of Large Language Models (LLM) for code and to empower the machine learning and open source communities through open governance.
Code LLMs enable the completion and synthesis of code, both from other code snippets and natural language descriptions, and can be used across a wide range of domains, tasks, and programming languages. These models can, for example, help professional developers and everyday citizens to build new applications.
The BigCode project is conducted in the spirit of open science. Datasets, models, and experiments are developed through collaboration and released to the community with permissive licenses. All technical governance takes place within working groups and task forces across the community.
As code LLMs are developed with data from the open-source community, we believe open governance can help these models to benefit the larger AI community. To ensure voluntary participation and recognition, we developed tools to give code creators agency over whether their source code is included in the training data and to find approaches that give attribution to developers when models output near-copies of the training data contained in the training data set that we’ve named “The Stack”.
Given concerns with the deployment and use of LLMs and emerging AI regulation, it seems like a good time to present the core aspects and tools of an open and collaborative governance process for developing an LLM.

Open and transparent development for LLMs
BigCode is an open governance interface for the AI and software communities. The governance process was developed in parallel to the LLM. Consequently, we took an open governance approach at every project stage.
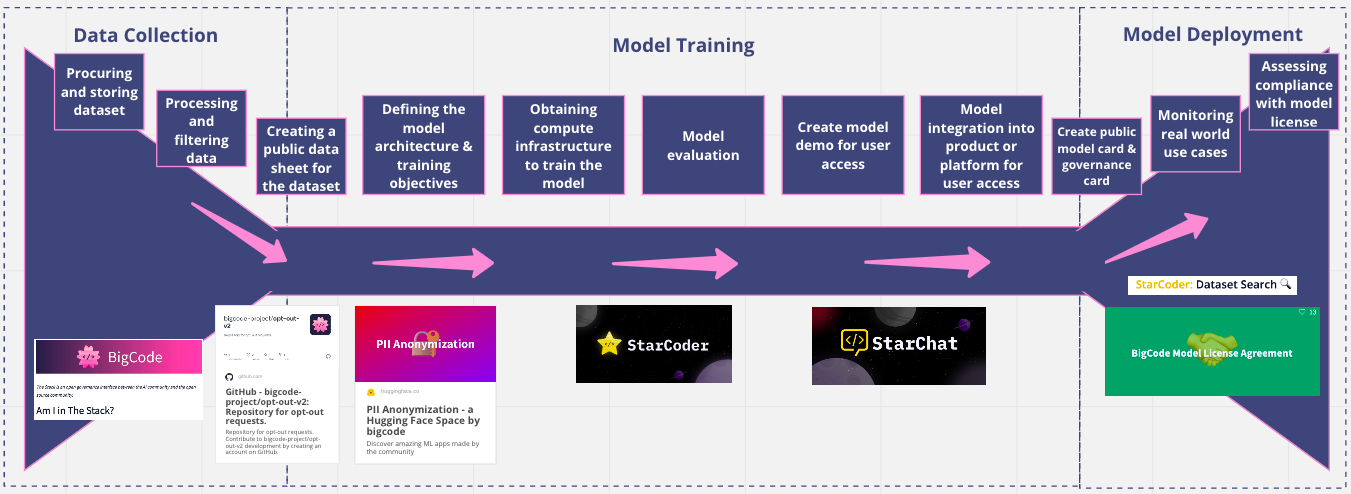
The training dataset, The Stack, is composed of permissively licensed data, i.e. code, and open for anyone to access, inspect and provide feedback. Even though the data collected was permissively licensed, and despite current legal uncertainty on using copyrighted material as training data, several governance mechanisms enabling the community to opt out and inspect the dataset were developed and released on an open basis.
Opt-out mechanism
BigCode gives people agency over their source code by letting them decide whether it should be used to develop and evaluate machine learning models. Not all developers want their data used for that purpose. “Am I in the Stack” is a tool for software developers to inspect whether their code was part of The Stack, i.e. the training dataset. If so, they can follow the opt-out process to have it removed from the training data.
Dataset maintenance
Even with the best of intentions, there can be glitches. Unfortunately, some software developers who wanted to opt out of the training dataset could not do so while LLMs were being trained. For this reason, BigCode made a dataset maintenance plan to provide regular updates to the dataset for the duration of the collaboration to remove opted-out data since the last version. If the collaborators are no longer able to maintain the dataset, they will stop distributing it in its current format and update the terms of use to limit the range of applications, including for training new LLMs. Finally, the dataset terms of use require people who download the dataset to agree to use the most recently allowed version to avoid using the removed data.
Attribution tool
BigCode developed and released StarCoder Dataset Search, an innovative data governance tool for developers to check if their generated source code or input to the tool was based on data from The Stack. If so, the tool returns the matches and enables the user to check provenance and due attribution. Tools such as this may pave the way for future attribution and revenue-sharing opportunities for generative AI applications and the code-creator communities the models rely on for training data.
Other relevant governance aspects
Privacy and fair wages
One significant risk was that the code LLM may generate private information found in its training data, including private tokens or passwords matched with identifiers or email addresses. Additionally, while users can and have requested that their personal data be removed from The Stack, removing specific information from trained model weights after the fact remains a technical challenge. To minimize this risk, BigCode chose to apply automated PII redaction at the pre-processing stage during training.
BigCode’s first step toward automatic PII redaction was to create an annotated dataset in code data. This is because neither regular expression-based approaches nor existing commercial software for PII detection met BigCode performance requirements. The annotated data set is meant to balance the constraints of costs or fair compensation. It also strives to appease time constraints and ensure that the work remains on the project’s critical path, meets quality requirements, and ensures that PII Detection Model training is not impacted.
While they considered traditional data annotation services with salaried employees, they decided to work with crowd-workers through Toloka. After reviewing several service providers and compensation practices, they found most would not provide sufficient transparency and guarantees for worker compensation.
BigCode selected pay rates and eligible crowd-worker countries to ensure that 1. the absolute hourly wage was always higher than the US federal minimum wage ($7.30), and 2. the hourly wage was equivalent to the highest state minimum wage in the US in terms of purchasing power parity ($16.50 at the time of writing). They engaged 1,399 crowd-workers across 35 countries in annotating a diverse dataset for PII in source code. BigCode PII detection model, trained on 22,950 secrets, achieves a 90% F1 score surpassing regex-based tools, especially for secret keys, i.e. how many PII instances are identified, with accuracy, or how many of the identified phrases are actually PII.
Sustainability: what’s the carbon footprint?
As in BigScience, BigCode reported the carbon footprint of training two LLMs, SantaCoder, and StarCoderBase. SantaCoder was trained on the ServiceNow cluster using 96 Tesla V100 GPUs, and StarCoder on a Hugging Face GPU cluster with 512 A100 80GB GPUs distributed across 64 nodes. The carbon footprint of training these models was calculated as follows:
- SantaCoder: Based on the total number of GPU hours that training took (14,284) and average power usage of 300W per GPU, this adds up to 4285 kWh of electricity consumed during the training process. Multiplied by the energy’s carbon intensity in the location, Montreal: 0.029 kgCO2e per kWh, and assuming an average Power Usage Effectiveness of 1.2, this results in 124 kg of CO2eq emitted.
- StarCoderBase: 320,256 GPU hours; 280W per GPU; 89671.68 kWh of electricity. The energy’s carbon intensity at the us-west-2 AWS location: 0.15495 kgCO2e per kWh; average Power Usage Effectiveness across AWS datacenters: 1.2. Total emissions: 16.68 tonnes of CO2eq.
It’s important to consider the full environmental impact when training a model, and what these summaries show is that in addition to the choice of hardware, the location of a data centre used for training matters. Even with similar data centre power efficiency, the ServiceNow Montreal data centre location used to train SantaCoder produces less carbon dioxide than the us-west-2 AWS data centre used to train StarCoder, located in Oregon.
Model governance and responsible AI licensing
These LLMs are released under an open and responsible AI model license agreement, BigCode OpenRAIL-M, which is available on the OECD Catalogue of Tools for Trustworthy AI. It enables royalty-free access, flexible use, and sharing and sets specific use restrictions for identified critical scenarios. Most importantly, the license agreement requires stakeholders who share the model or a modified version of it: (i) to include the same set of use restrictions or a similar one in their legal agreements; (ii) to keep the model card and provide a similar one or one of better quality when sharing a modified version of the model ( see FAQ for the model license agreement).
The BigCode OpenRAIL-M license agreement, i.e. the legal document itself, is available under a CC-BY-4.0 license. Therefore, any stakeholders can freely adopt the same license agreement for their models or modify it for their AI artefacts. Both the RAIL Initiative webpage and The Turing Way Handbook for ML researchers (Alan Turing Insitute) have more information about responsible AI licensing; so does this OECD.AI blog post on RAILs and trustworthy AI principles.
The StarCoder Governance Card
The StarCoder Governance Card is new and used to document governance processes and tools. The Governance Card serves as an overview of mechanisms and areas of governance in the BigCode project. It promotes transparency by providing relevant information to a wider public about choices made during the project and is an example of intentional governance in an open research project. Future endeavours can leverage it to shape their own approach.
It takes inspiration from standard documentation practices in AI, such as model cards, and more consumer-oriented cards, such as Meta’s AI System Cards, Microsoft’s Transparency Notes or Cohere’s model cards. The Governance Card can inform policy makers about the documentation and transparency potential that open scientific endeavours in AI have.
BigScience and BigCode prove the AI community can be leveraged to set open and collaborative governance frameworks. In the spirit of fostering more openness and governance interfaces in the AI community, BigCode hopes this article can inform future governance practices closely articulated with international AI policy.



