


























Establishing the shared foundations for collective AI security








Emerging AI capabilities in coding, tool utilisation, and multi-step reasoning, which is core to agentic AI, are shaping a more complex digital security environment. AI-based applications and services are becoming increasingly integrated into software, public services, vital sectors, and the broader economy, offering new opportunities for productivity and innovation. However, they also introduce new types of security exposure – misconfigurations and weaknesses that can lead to unauthorised access.
What AI security means in practice
AI security builds on traditional cybersecurity and goes beyond it. Today’s AI applications are trained on vast, diverse data and increasingly embedded in workflows that retrieve information, use tools, store memory, and perform multi-step tasks. Distinct AI security risks arise because models learn from data, behave probabilistically, and, in agentic systems, act more autonomously.
Many of the most important AI security risk patterns are only beginning to emerge. The evidence base remains uneven across issues such as prompt injection, agentic misuse, model poisoning, and the security of connected tools. AI technologies are by nature cross-border and cross-sectoral, meaning that no single country, company, or institution can adequately address the security challenges they create alone. This is especially true as AI agents become more capable and more embedded in real-world contexts.
Because AI models and applications operate across borders, security measures require international cooperation on shared methods, common tools and information-sharing channels. The same foundational research can also support adjacent safeguards, from content provenance against deepfakes to safer AI chatbot design.
To meet new security requirements, AI developers and governments across jurisdictions and sectors will need to drive additional joint research, more comparable evaluation methods and robust best practices. These should cover the full AI security lifecycle, from protecting models and pre-deployment assets such as model weights and datasets to the security and resilience of AI applications and services during deployment, especially in critical sectors.
A first approach to strengthening AI security requirements would be to pool resources across three areas: resilience against scalable, reusable attacks, such as prompt injection, particularly at the interaction layer; ensuring the secure connection of AI agents to tools and services; and strengthening safeguards for models, model weights, and training data integrity.
Priority 1: Defending against transferable and automated prompt-injection attacks
Direct and indirect prompt-injection attacks are becoming more reusable, scalable, and security relevant. That is why security researchers at the Open Worldwide Application Security Project (OWASP) rank prompt injections among the most prevalent AI security risks. While evidence on transferability is still developing, recent research suggests that some attacks can be adapted across harmful tasks and, in some cases, across different models.
For example, an AI assistant used in a workplace might be asked to summarise a document or webpage. If that content contains hidden malicious instructions, the system could be manipulated into ignoring the user’s request, revealing sensitive information, or taking an unintended action. That raises practical questions for enterprise deployment, testing, and incident response.
This matters because reusable or automated prompt-injection methods reduce attacker costs and make attacks easier to repeat. For policymakers, this shifts the question from whether a model can be bypassed in a lab setting to whether it remains resilient to attacks that are reused, adapted and improved over time.
The frontier security community should prioritise understanding why some prompt-injection attacks transfer more readily than others and develop evaluations that reflect adaptive, automated attack strategies. Rather than simply blocking known prompt patterns, they should also identify techniques that improve robustness. Recent benchmark work from MLCommons, a technical safety organisation, suggests that classifying attacks by model-manipulation techniques would help evaluators get closer to the underlying mechanisms of vulnerability.
Automated prompt-injection techniques are becoming more transferable and scalable, making it easier to discover, reproduce and act on vulnerabilities across systems. Evaluation capacity will therefore need to support ongoing assessment of how advances in frontier AI may accelerate vulnerability discovery and exploitation. This will be critical both for ensuring defensive testing keeps pace with evolving attack methods and for helping countries use AI more effectively to strengthen cyber resilience.
International collaboration could improve prompt injection evaluations and universal jailbreaks by making it easier to identify reusable and transferable vulnerabilities. International collaboration could improve evaluations of prompt injection and universal jailbreaks by identifying reusable and transferable vulnerabilities. It could also help to direct research investments from governments and frontier labs toward more robust evaluations and more durable defences.
Priority 2: Securing AI agents
AI agents create a new set of security challenges. Attacks can manipulate content before an agent application retrieves it, misuse connected tools, or hide malicious instructions in documents processed by the agentic system.
Consider an AI agent connected to email, calendars or payment tools. With broad permissions and malicious instructions, failures can become concrete: the agent may share sensitive information, trigger unwanted actions, or move the user’s money in unintended ways.
Because agents can plan tasks, use tools, retain memory and interact with other systems, each capability creates new opportunities for misuse and failure. Three examples illustrate this challenge:
- Memory poisoning: Attackers insert malicious content into an agent’s memory or long-lived context, causing harmful behaviour that goes undetected and persists in future interactions.
- Tool misuse: As AI systems adopt standardised methods, such as the Model Context Protocol (MCP), to connect to external tools, databases, and services, weak identity controls or excessive permissions can create new security gaps.
- Context-based instruction attacks: Malicious instructions are hidden in emails, documents, or web pages and then retrieved by an agentic AI system, which treats them as part of its working context, potentially leading to unintended actions or data leakage.
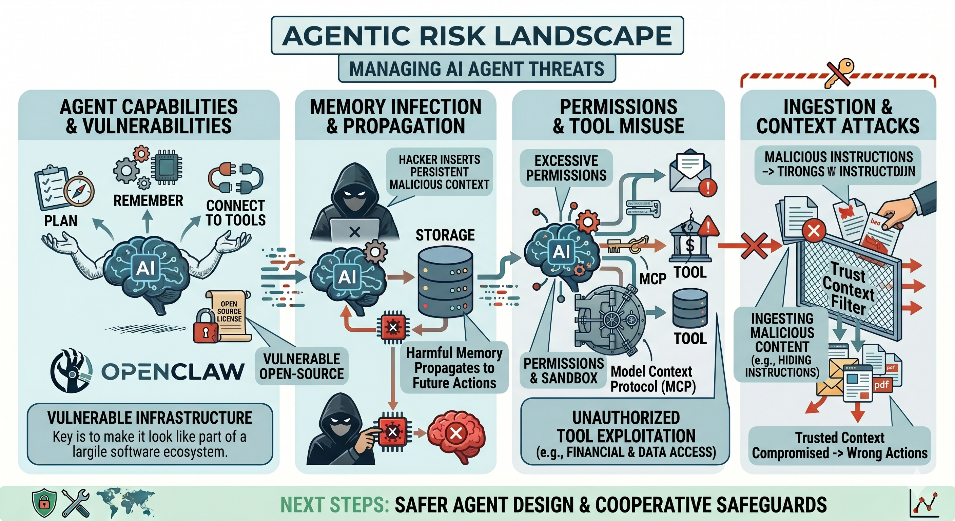
These patterns go beyond traditional threat models. Recent work, including OWASP’s Top 10 for Agentic Applications, reflects a broader recognition that memory, connected tools, identity, permissions and multi-step autonomy create a distinct security profile for agentic systems.
Developments in the financial sector illustrate how quickly these questions are becoming pressing. On 2 March 2026, Banco Santander and Mastercard announced what they described as Europe’s first live, end-to-end payment executed by an AI agent within a regulated banking framework. As agentic AI systems move into higher-stakes domains, coordination on security baselines and implementation practices will become increasingly important.
AI agents will need to be made secure by design, and the external tools and services they connect to will need to be made secure. Design improvements could include stronger memory safeguards, better permission design and more effective sandboxing. Measures to make services reliant on agentic AI more robust could include research into deterministic controls that constrain how an agent can transfer information among untrusted content, memory and tool actions.
Cybersecurity institutions need to be involved from the beginning because issues related to AI agents—such as permissions, connected tools, and secure deployment in sensitive settings—build on well-understood challenges faced by cyber agencies. International collaboration among AI Institutes could help adapt existing security practices to agentic systems, identify shared vulnerabilities, and promote more uniform methods for testing, incident management, and secure deployment.
Priority 3: Detecting and mitigating model poisoning
Model poisoning happens when attackers introduce vulnerabilities or alter a model’s behaviour by manipulating training or fine-tuning data. Until recently, it was often assumed that this would require control over a significant share of a model’s training data, implying that larger models trained on broader datasets would be harder to compromise.
Recent research challenges this assumption. Work published in 2025 by Anthropic, the UK AI Security Institute and the Alan Turing Institute found that a relatively small number of malicious documents (as few as 250) could be enough to introduce a backdoor into models of very different sizes. Researchers at Carnegie Mellon’s CyLab have similarly demonstrated that manipulating as little as 0.1 per cent of a model’s pre-training dataset is sufficient to launch effective data poisoning attacks.
In practice, this means that poisoned content can propagate through the AI supply chain, shaping the behaviour of downstream models even when the original model developer has not been directly compromised.
That can have serious consequences for the security of open-weight models. An attacker could seed a small number of poisoned public documents that would propagate into multiple downstream training runs and forks without access to the original developer’s pipeline.
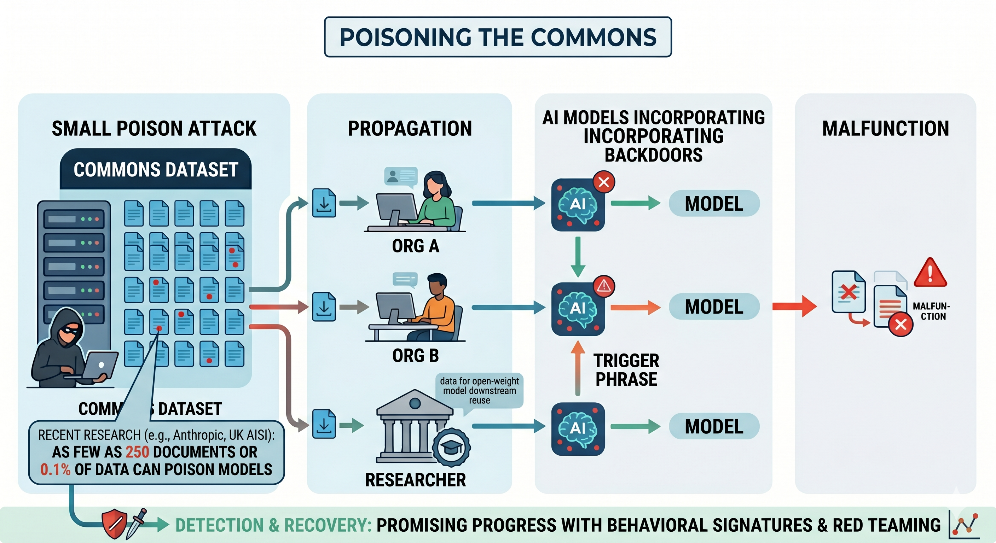
Promising research by Microsoft’s AI Red Team has explored ways to detect backdoored models at scale after they have been trained and shared. Early techniques identify poisoned models by analysing behavioural signatures and links between backdoors and memorisation, pointing to a promising solution in a previously difficult-to-detect risk area.
However, simply demonstrating that poisoning is possible is not enough. Research to improve the detection of compromised models and to strengthen safeguards during training and fine-tuning would help. So would developing more practical methods for recovery when poisoning is suspected. Promising research techniques are emerging, but they are not yet reliable across all models and deployment settings. This is where coordinated action and international collaboration among universities, frontier labs and AI institutes would be particularly valuable.
What shared AI security could look like in practice
These three security priorities show that no country is likely to build the necessary evidence base, testing capacity and operational practices on its own. The more effective objective is therefore to strengthen the foundations of shared AI security: maturing best practices, advancing targeted research, building clearer expectations around deployment conditions and improving cross-country coordination in ways that support more secure adoption over time.
Practical progress can start by establishing building blocks that enhance interoperability and gradually boost the effectiveness of national efforts.
International efforts led through the G7 and the OECD – GPAI are well placed to advance this agenda through a few practical building blocks :
- Shared benchmarks and testing environments are essential. Countries and research organisations require standardised methods to evaluate poisoning risks, agentic vulnerabilities, indirect prompt injections and resilience to jailbreaks across various models and deployment scenarios.
- Better channels for information-sharing on vulnerabilities. AI-related vulnerabilities often do not align well with existing cyber-disclosure procedures. Enhancing AI security calls for reliable means for sharing exploit techniques, mitigations and lessons learned in ways that support both transparency and the secure handling of sensitive information.
- Common reference points for secure design. International coordination can help align threat-modelling practices that clarify emerging failure modes, risk-management approaches that translate those risks into governance best practices and security standards for critical components and infrastructure, including model weights. Together, these can support more secure implementation in practice.
- Enhanced public-private dialogue. AI security is evolving too quickly for governments, researchers and companies to work in isolation. Regular exchange channels can help policymakers understand emerging risks while giving researchers and firms clearer signals on where shared benchmarks, disclosure practices and secure design guidance are most needed.
AI institutes, including members of the AI Network for Advanced AI Measurement, Evaluation and Science, can help align evaluation priorities and testing methods. Universities and independent researchers can deepen the knowledge base in fast-moving domains where attack and defence techniques evolve rapidly. Cybersecurity authorities can help turn emerging lessons into operational practices for secure deployment, especially in higher-stakes environments.
These communities should invest in resources, tools, policies, and operational capabilities to assess how frontier AI might. speed up vulnerability discovery. Beginning with France’s G7 Presidency, the next immediate steps could facilitate closer alignment on key research and evaluation priorities and improve information-sharing channels to manage these risks effectively.
For nations aiming to expand AI throughout their economies, integrating security into AI development and deployment processes will be crucial to promoting AI diffusion and adoption. As new models develop stronger reasoning and coding capabilities, governments, researchers, and companies will need better ways to measure their capabilities and define limitations. That makes shared research roadmaps, stronger testing methods and practical security practices more urgent for trusted deployment.



