


























Rethinking AI data: From scraping to sustainable and ethical data sharing





Marie Langé, Aurélie Aurélie, Bertrand Monthubert, Jean Constantin, Yann Dietrich
March 31, 2026 — ![]() 6 min read
6 min read




The AI data paradox
As our daily activities become more digitised, from ordering dinner to receiving medical care, the amount of data produced by humans and machines continues to grow each year. The internet provides a seemingly limitless flow of accessible data of all formats and natures, from news sites to social media. In early 2026, the internet archive initiative CommonCrawl boasted over 300 billion webpages in its database. Adding to this digital abundance, even larger volumes of data remain underused and locked in organisations’ private databases. Meanwhile, IBM reports that in 2024, the biggest challenge for AI developers was a shortage of high-quality data. This is the AI data paradox: despite an abundance of data globally, AI developers face a scarcity of usable data, with growing expert concerns about a looming data crunch as reported by the OECD (2025).
The new GPAI-associated report, From scraping to ethical data sharing, produced under the VIADUCT initiative, addresses this paradox. Based on 25 interviews and two multistakeholder workshops held in 2025, the report complements the OECD’s Recommendations on Enhancing Access to and Sharing of Data (EASD, 2019) and grounds its analysis in the concrete challenges faced by both data holders and AI developers when sharing and accessing data.
Scraped internet data as a key source for AI training
Data is the cornerstone of modern AI development, from model training to grounding. As online public content continues to grow, it has become a major source of training data for AI models. Initiatives such as CommonCrawl and LAION have harvested, or “scraped”, billions of online pages and images, ranging from news articles and government websites to blogs and social media. These datasets fuel rapid advances in AI tools, but also pose deep challenges.
Figure 1: The AI data value chain: From scraping data for reuse to content to generation
Contemporary AI requires contemporary data sourcing methods
As investment and revenue flow, AI has become a major industry, but data-sourcing methods have not kept pace. Many current AI processes still rely heavily on scraping large amounts of public content, often without permission, proper compensation or quality controls. But this “grab what you can” approach has limits. As the report documents, over 50 copyright and data protection lawsuits have been filed worldwide, while websites are increasingly deploying technical and contractual barriers to prevent scraping. At the same time, the web is increasingly saturated with low-quality material, including AI-generated “slop” and disinformation. Meanwhile, vast amounts of valuable data remain locked away on private servers because concerns about legal risk and confidentiality inhibit sharing.
These quality challenges and legal pressures point to the need for a new approach, one that moves beyond extraction towards mutually beneficial data-sharing arrangements, including commercial and non-commercial agreements as described in the OECD’s Mapping Relevant Data Collection Mechanisms for AI Training report (2025). Instead of relying on a single technical solution, the VIADUCT report presents data sourcing as a systemic challenge at the intersection of law, economics and technology. While data infrastructures have expanded significantly, experience shows that technical capacity alone does not initiate data flows.
Data sharing as a transaction
If not a simple engineering problem, then what is data sharing? At its most basic, data sharing is a transaction between two parties.
For common assets such as treasury bonds, Brent crude oil or soda cans, industry standards, regulations and institutions support transactions and build market trust. By contrast, data is not a standard asset. It is a collection of diverse assets that take different forms, with varying stakeholders and regulatory requirements. Consider two datasets: one with hospital patients’ X-rays, and another with archived news articles. The first dataset contains sensitive personal information protected under the GDPR in Europe and must comply with the principles of confidentiality and consent. News articles in the second dataset are copyrighted works whose owners can prohibit reproduction and opt out of AI training under EU law. These simple examples show that sharing data cannot rely on technology alone but must also consider a dataset’s economic, legal and social contexts and constraints.
Data is not monolithic
Government officials and business leaders often use metaphors like “raw material”, “new oil” and “gold” to describe data. However, contrary to what these metaphors suggest, data is not a uniform resource. In its EASD in the age of AI (2025), the OECD describes data as “recorded information in structured or unstructured formats, including texts, images, sound, and video”, which may also include AI models themselves when training data is memorised. On top of its diversity of shapes and formats, data is also a mosaic of digital assets, each governed by different rules, logic and constraints. Is one dealing with a copyrighted news article? Personal health records? A company’s trade secrets? Government statistics? Open source software code? Understanding this is essential to designing sustainable AI data ecosystems. Each type of data has its own legal guardrails, economic dynamics and technical challenges.
The VIADUCT report classifies data into five governance regimes according to the EU legal framework:
Figure 2: Data governance regimes under EU law
| Governance model | Data scope | Dataset example |
| Copyrighted content | All creative works, including texts, images, videos, sounds, software source code and certain databases. Authors have exclusive rights to reproduce, communicate and distribute their works. They can also opt-out of commercial AI processing. | News article dataset, book archive, social media posts, music database |
| Personal data | Any data or information relating to an identified or identifiable individual (“data subject”). Under EU’s GDPR, a data processing, such as AI training, must be transparent, confidential, minimal and motivated by legal grounds such as data subject consent, or controller’s legitimate interest. | Customer history database, patients’ medical records, mobile phone GPS locations |
| Trade secrets | A dataset which is secret, is safeguarded and holds value due to its secrecy. Companies are protected against unlawful access, and can share trade secrets with third parties under strict safeguarding measures. | Engineering blueprint files, pharmaceutical molecule database, commercial lead database |
| Public sector data | Under EU law, public sector bodies must publish their documents for commercial and non-commercial reuse, free from exclusive license and without fee beyond cost compensation. | Texts of law, national statistics, national company registry |
| Open data | Any data which can be accessed, shared and used by anyone for any purpose, free of charge. In Europe, this may include contents with expired copyrights, government documents, and open-license content | 19th century books, Wikipedia articles, open-source software code |
Three guiding principles for sustainable and responsible approaches to data sharing for AI
In this diverse and complex environment, the report sets out three clear guiding principles that apply to all data types and governance regimes to foster sustainable and ethical data sharing for AI.
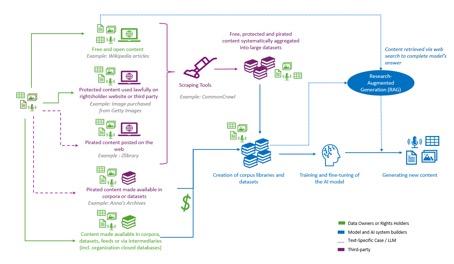
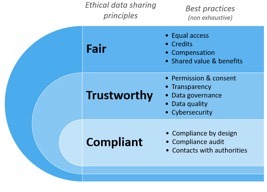
Legal compliance is the first principle. Data sharing and downstream use must respect applicable legal frameworks. In Europe, this includes honouring copyright holders’ rights, establishing legal grounds for the use of personal data and protecting confidential trade secrets.
The second is trust. Data holders need assurance that their data will be used only for permitted or legitimate purposes and protected by robust cybersecurity measures. Data consumers, in turn, need confidence that datasets are legitimate, accurate and of high quality.
The third principle is fairness. Data-sharing arrangements should be mutually beneficial, crediting organisations that support AI development and, where appropriate, sharing the benefits.
Figure 3: Ethical data sharing principles and best practices
Constraints for ethical data sharing
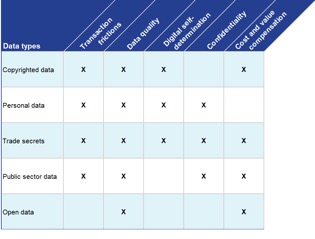
These principles sound simple, but applying them in practice is challenging. Exchanging large volumes of data requires expertise, which is often lacking in smaller organisations, and the process is fraught with technical, legal, and economic frictions. Data quality issues are a major source of friction, as errors, inappropriate content or bias can create risks and costs for downstream AI use. Ensuring data holders maintain control of their data after sharing or publishing is essential. This is referred to as digital self-determination. This is the case for personal data, copyrighted content or trade secrets, for which the data holder must often grant permission for each new processing act. EU law imposes strict confidentiality standards for personal data, trade secrets and sensitive government data. Finally, to incentivise data sharing and ensure its sustainability for data holders, implementing appropriate economic models such as cost and value compensation appears to be an essential solution.
Figure 4: Ethical data sharing constraints
Transitioning to a multidisciplinary and implementation-focused approach
This non-exhaustive list of challenges illustrates the limits of relying only on normative or technical responses to address data-sharing constraints. The report investigates alternative approaches, such as opt-out methods, smart contracts, data attribution and privacy-enhancing technologies.
When it comes to ethical data sharing, moving from Is it possible? to How can we implement it? requires developing actionable tools and recommendations to address challenges. Given their diverse and context-sensitive nature, VIADUCT facilitates dialogue among data holders, AI developers, policymakers and researchers on concrete data-sharing projects and experiments. Ultimately, this exercise seeks to create a better understanding of the challenges for data sharing and promote and test innovative solutions at the crossroads of technology, economics and law.



