


























Ensuring AI’s trustworthiness: reliability engineering meets data-driven risk management







This blog explores the application of reliability engineering principles to AI systems to ensure their safety and performance. We discuss the use of concepts such as the “bathtub curve”, Mean Time to Failure (MTTF), and Mean Time Between Failures (MTBF) to anticipate and manage potential AI system failures in a proactive manner. It also emphasizes the importance of considering human factors in AI system reliability to help inform a data-driven regulatory framework for AI safety. Newly emerging frameworks like the NIST AI Risk Management Framework, Singapore’s Model Governance Framework & AI Verify, the EU AI Act, Blueprint for an AI Bill of Rights, Foundational Model Transparency Index, the OECD’s Catalogue of Tools and Metrics, underline the relevance and urgency of such approaches.
Reliability Engineering: the foundations for AI safety
Ensuring AI systems’ safety has become a central concern as we increasingly integrate them into our daily lives. At the heart of this discourse is a field that has guided the reliability of complex engineering systems for decades: reliability engineering.
Reliability engineering is about applying scientific know-how to a system, ensuring it performs its function without failure over a specified period. It quantitatively models system failures using a combination of probabilistic and AI methods, giving us valuable measures such as the Mean Time to Failure (MTTF) and the Mean Time Between Failures (MTBF). These mathematical concepts are fundamental in complex systems like AI, providing the foundation for understanding and managing potential risks. The role of time is at the heart of reliability mathematics. The increasing adoption of international frameworks for AI risk assessment further underscores the importance of using standard reliability engineering principles.
Incorporating Prognostics and Health Management (PHM) into AI systems elevates this foundational safety approach by leveraging predictive analytics and machine learning, enabling proactive maintenance and anomaly detection. By continuously monitoring and analysing the health and performance of AI systems, PHM provides an extra layer of safeguarding, helping to prevent catastrophic failures. This approach aligns well with global regulatory trends and emphasises the need for comprehensive risk management in the AI lifecycle. Let’s examine how these principles apply to AI safety.
Early detection and planning for AI projects
In the dynamic world of Large Engineering Projects (LEPs), the stakes are high, and the biggest impact on shaping the outcomes is at the initial stages. This project lifecycle is illustrated in Figure 1, where we see the significant impact of decisions made in the pre-project phase (marked as an orange box). The project cost is increasing, while the level of influence on project outcome is declining. From an AI system perspective, the pre-project phase is a kaleidoscope of critical considerations, encompassing data intricacies, quality, standards, model innovations, computing infrastructure choices, as well as privacy concerns, socio-economic ramifications, domain-specific problem-solving objectives, economic impact, both positive and negative externalities.
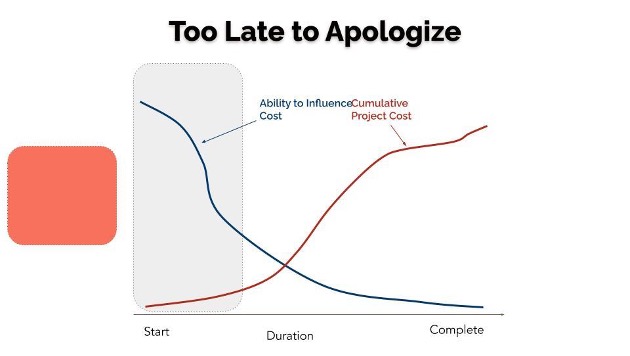
Source: Adapted from Laufer, 1997.
The bathtub curve
Reliability engineering uses a concept called the “bathtub curve” to model the lifecycle of engineering systems, outlining three distinct phases of failure rates: early failures, random failures, and wear-out failures.
Imagine a newly built car. Initially, it might have many problems. electrical issues, leaks, etc. There may be scope creep, design issues, unanticipated conditions, execution flaws, and partner disputes or failures. As these issues get addressed, the car enters a period of relatively steady operation with a stable failure rate – the “Useful Life” or random failure phase.
Finally, as the asset ages, parts wear out, leading to an increased failure rate – the “Wear-out” phase could include hydraulic, collision or overload. This progression, from high to low to high failure rates, gives the graph its bathtub-like shape.
The bathtub curve and the AI life cycle
In AI systems, the early failure phase could be during the design and development stages. Failures during this phase might result from flaws in algorithm design or inaccurate training data. The “Useful Life” phase would correspond to the AI system being in operation, where failures could arise randomly due to unexpected inputs or conditions. Unpredictable inputs or unforeseen situations can trigger failures during this phase.
Lastly, the wear-out phase might manifest as an AI system’s performance may start to degrade, either because the algorithms become obsolete or the patterns in the new data evolve beyond the system’s training scope. Understanding this pattern allows AI developers and operators to anticipate potential failures and implement proactive measures to maintain AI system safety throughout its lifespan.
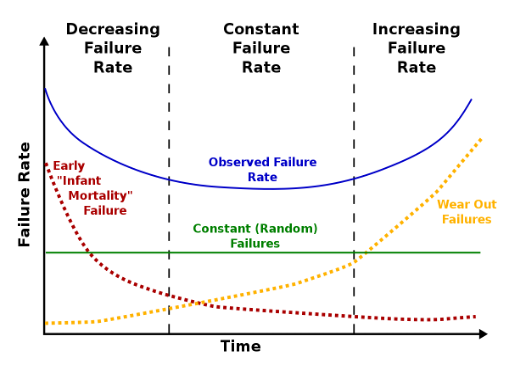
Notes: The ‘bathtub curve’ hazard function (blue, upper solid line) is a combination of a decreasing hazard of early failure (red dotted line) and an increasing hazard of wear-out failure (yellow dotted line), plus some constant hazard of random failure (green, lower solid line).
Source: Maisonnier (2018).
Understanding AI system reliability
Imagine using popular AI systems like voice assistants (Siri, Alexa) and Large Language Models (LLMs) like ChatGPT. Their reliability is crucial for our daily interactions. To quantify this, we use specific mathematical functions that could be important for AI regulation and policy.
Reliability function: Reliability function is the probability that a system (component) will function over some time period t. To express this relationship mathematically we define the continuous random variable T to be the time to failure of the system (component); T 0. We will refer to R(t) as the reliability function and F(t) as the cumulative distribution function (CDF) of the failure distribution. Similarly, a third function is called the probability density function (PDF), which describes the shape of the failure distribution. These three figures are illustrated in Figure 3. The reliability function and the CDF represent areas under the curve defined by f(t).
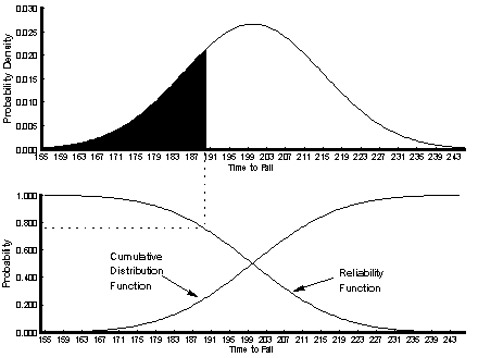
Mean Time to Failure (MTTF): Think of this as the average lifespan of an AI system before it slips up. It’s the expected run-time or how long the system offers acceptable and intended performance before showing any clear sign of depreciation, malfunction, or any error, i.e. the average time we expect a system to run before it fails. The MTTF is defined by the mean, or expected value, of the probability distribution defined by f(t),
Mean Time Between Failures (MTBF): If you have a system that can be fixed and reused, MTBF is the average time between one failure and the next. This helps in planning repairs and understanding the system’s reliability. MTBF is a measure used to quantify the average “up-time” of a system that can be repaired. It represents the average time duration between two successive failures of the system during its operation. To understand this, consider a system that goes through cycles of operation and failure. The moment the system starts operating after a failure is considered the “up-time”. The system continues to operate until it encounters a failure, at which point it goes “down”. This moment of failure is the “downtime”. The duration of operation between the “up-time” and the “down time” is the time the system was functioning without failure. MTBF is the average of these durations over multiple cycles of operation and failure (Modarres et al., 1999). Figure 4 provides an example of these concepts.
Defining failure in AI: Any underperformance in an AI system, considering the initially defined intended functionality, can be considered a failure of an AI system. In reliability engineering, a failure point is typically a deviation from expected behaviour, whether that’s producing an incorrect output or crashing entirely. Engineers usually gather data on the frequency, nature, and conditions of these failure incidents to get a clear picture of reliability. One pressing question for the global policy community is finding consistent ways to collect and share data on AI failure incidents across different sectors and regions.
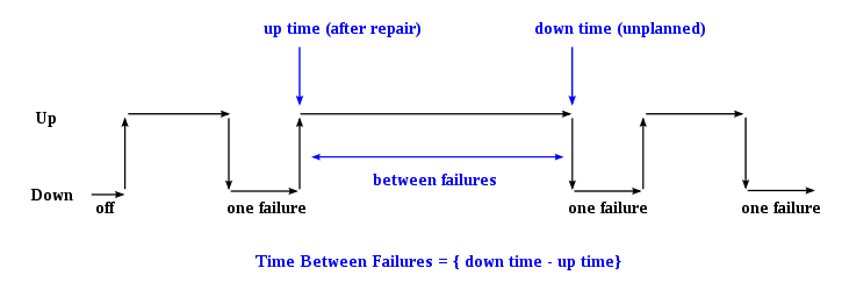
Notes: MTBF is the “up-time” between two failure states of a repairable system during operation. Note that MTTF metric is associated with non-repairable components, whereas MTBF metric is related to repairable components.
Source: Wikimedia commons.
Human-centric AI and reliability
Originating during World War II to prevent human and cognitive errors in complex fighter jet modules, the field of Human Reliability now intersects with AI. Human factors, from data labelling errors to biases in algorithm design, can introduce system failures. When humans influenced by AI systems make decisions, it is important to consider the system comprehensively and account for the human and AI systems collectively.
For example, a medical professional, misled by an AI diagnostic tool’s flawed data, might give harmful advice. Emphasising human factors, reliability engineering ensures AI safety remains human-centric, bridging past lessons with future innovations. Here are some examples of human factors that have contributed to different types of AI system failures, based on early failures, random failures and wear-out failures.
Early failures
- Chatbots: Microsoft’s chatbot Tay, released in 2016, began tweeting offensively due to user interactions and inadequate developer foresight. This highlights the need for thorough AI testing and understanding potential human-AI interactions.
Early failures often result from a lack of thorough testing or understanding of the environment in which the AI system will operate. The human factor here was the inability to foresee the wide range of human-AI interactions and to implement necessary precautions.
Random failures
- Autonomous vehicles: In 2018, an Uber self-driving car struck a pedestrian in Arizona. The AI system wasn’t trained for jaywalking scenarios, pointing to the unpredictability of human behaviour and the need for comprehensive AI training.The AI system could not predict and respond to a situation it was not trained on. The human factor includes the design and training of the AI, as well as unpredictable human behaviour in the AI system’s operating environment.
Wear-out failures
- Content recommendation systems: Platforms like YouTube may trap users in a “filter bubble” over time, suggesting only a narrow content type. This algorithmic over-optimization results from feedback loops where users engage with similar content, emphasising the need for diverse AI training. As the system “ages” and accumulates more data on user behaviour, it might overfit this data. The wear-out here is not physical but represents a degradation in the quality of the system’s outputs. The human factor might be feedback loops where users only click on recommended content, further reinforcing the system’s narrowing boundaries.
Human factors in AI failures can be intricate. Both the design and human interaction significantly influence AI performance. Regulatory frameworks should address technical and human aspects to ensure AI system safety.
Policy considerations for AI reliability and autonomy
AI policies should integrate reliability engineering concepts to balance safety and innovation. Regulations might require transparent incident reporting to guide reliability calculations. This data can pinpoint AI system lifecycles and failure root causes, fostering tech accountability. Assuming the incidents are defined and data are available on failure events, MTTF and MTBF offer a mathematical framework to model these unexpected behaviours, providing an early warning system for potential issues and enabling the development of safeguards to mitigate them.
In AI system reliability, accounting for where in the spectrum of human-in-the-loop versus fully autonomous systems like high-risk military applications or ‘autonomous defence systems’ might be crucial. Human factors impact the system lifecycle, influencing everything from initial planning to real-world applications. For autonomous systems, including military applications or the Mars Rover, self-sufficiency and rapid decision-making are key. Human oversight remains essential for strategic guidance and as a fail-safe. NASA’s case studies highlight that AI autonomy extends beyond automation or intelligence, focusing on self-directed efficiency in situations requiring rapid, on-board decision-making.
Reliability engineering is particularly critical for safety-critical AI applications, including those affecting human rights. These considerations are becoming increasingly important in emerging policy frameworks. However, it’s important to recognise that reliability engineering is not a cure-all for AI safety issues. It’s one possible crucial aspect. AI as a field is highly multidisciplinary and data-driven; hence, formulating comprehensive policy guidance in AI should be multi-disciplinary and data-driven. Often, risks associated with AI are not fully apparent during development and testing but emerge post-deployment or during interaction with external environments. Therefore, risk identification and mitigation in AI applications can be a continuous process, occurring at various points in the AI value chain, creating multiple, sequential and partly overlapped “bathtubs”.
Merging AI safety with reliability engineering is potentially vital for effective policymaking and business growth. As we tap into AI’s potential, grounding its development in reliability engineering ensures AI systems are highly safe and reliable as they are innovative.



